|






 |  |

| Afaceri | Agricultura | Comunicare | Constructii | Contabilitate | Contracte |
| Economie | Finante | Management | Marketing | Transporturi |
Economie
|
|
Qdidactic » bani & cariera » economie Modele econometrice |
Modele econometrice
MODELE ECONOMETRICE
1.1. Generalitati
Modelarea economica reprezinta un proces de cunoastere mijlocita a realitatii cu ajutorul unui instrument cu caracteristici speciale: modelul. Sistemul real supus studiului este inlocuit prin modelul sau, care este o reprezentare simplificata a obiectului cercetat.
Modelul econometric este, de regula, o multime de relatii numerice care permite reprezentarea simplificata a procesului economic supus studiului (uneori chiar a intregii economii). Modelele actuale comporta adesea mai mult de zece relatii (ecuatii). Validitatea unui model este testata prin confruntarea rezultatelor obtinute cu observatiile statistice. Pentru a studia un fenomen economic se incearca reprezentarea lui prin comportamentul unei variabile. Aceasta variabila economica depinde, la rindul sau de alte variabile de care este legata prin relatii matematice.
De exemplu, daca se studiaza cererea (C) si oferta (O) dintr-un anumit bun pe o piata, se stie ca cererea si oferta depind de pretul (p) bunului respectiv. Putem scrie ca variabilele C si O sunt functii de variabila p si ca la echilibrul pietei, trebuie ca cererea sa fie egala cu oferta. Se construieste astfel un model elementar de forma:
[1] 
Oferta si cererea dintr-un anumit bun depind si de alte variabile decat pretul. Astfel, cererea dintr-un bun alimentar depinde si de venitul disponibil, de pretul unor produse analoage etc. La fel, daca este vorba despre un bun agricol (grau,) oferta depinde de pretul anului precedent. Relatia stabilita intre variabile in modelul econometric este data, de regula, la un anumit moment de timp t, caz in care variabilele apar indiciate:
[2] 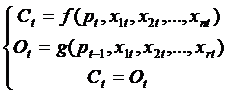
In modelul [2] s-au introdus mai multe variabile care explica cererea si oferta dintr-un bun si s-a considerat realizarea acestor variabile la momentul t sau t-1. Se observa ca modelul comporta mai multe relatii. Se zice ca avem un model cu ecuatii multiple. Evident, se va incepe studiul cu un model mai simplu, cu o unica ecuatie.
1.2. Model aleator
Sa presupunem ca se studiaza consumul (Ci) dintr-un anumit bun de catre o familie (i). Intre alte variabile, consumul depinde de venitul disponibil al familiei (Vi). Modelul econometric elementar consta in a exprima Ci in functie de Vi. Desigur, alti factori - dintre care unii sunt necunoscuti - determina de asemenea consumul familiei. Condensam efectele acestor alti factori intr-unul singur, aleator, notat εi. Se obtine astfel un model aleator:
[3] ![]()
Factorul aleator εi este o variabila aleatoare care urmeaza o anumita lege de probabilitate, ce va trebui sa fie specificata prin ipotezele facute asupra modelului. Cel mai frecvent, ipotezele se refera doar la momentele de ordinul I si II ale variabilei aleatoare εi. Urmeaza sa ne asiguram ca functia f (sau clasa de functii) aleasa nu contrazice rezultatele experientei. De exemplu, daca s-a ales f ca o functie liniara (adica f(Vi) = aVi+b), modelul econometric este:
[4] ![]()
si variind pe i pentru diferitele familii studiate, ne vom asigura ca relatia [4] este bine satisfacuta. Se spune ca "testam" modelul. Daca rezultatul obtinut este convenabil, se va trece la "estimarea" parametrilor a si b. Apoi, definind o "regula de previziune" se va putea determina consumul Ci daca se cunoaste venitul Vi.
1.3. Natura variabilelor care apar in model
Intr-un model econometric se disting doua tipuri de variabile:
-exogene. Sunt variabilele explicative ale variabilei studiate si se considera ca fiind date autonom. In modelul [4] Vi este variabila exogena (sau explicativa, independenta). Venitul familiei Vi explica in acest model consumul familiei Ci. Valoarea variabilei exogene -pentru un i dat si pentru εi precizat- permite determinarea consumului Ci.
-endogene. Sunt variabilele de explicat (sau dependente). Ci este variabila endogena in modelul precedent. Se poate remarca faptul ca Ci este acum o variabila aleatoare datorita lui εi.
Distinctia intre natura variabilelor este foarte importanta si va trebui precizata intotdeauna inainte de a studia modelul. Cand modelul econometric a capatat formularea matematica definitiva se spune ca modelul a fost "specificat". Modelul [4] de mai sus este specificat. Se cunoaste forma functiei f din expresia Ci = f(Vi) + εi , adica f(Vi) = aVi+b. Adaugarea variabilei exogene εi da modelului formularea definitiva [4].
Multimea parametrilor care definesc complet modelul econometric constituie "structura" acestuia. De exemplu, daca a = 0,7 si b = 23 iar ε urmeaza o lege de probabilitate normala de medie (speranta matematica) egala cu zero si dispersie (varianta) egala cu 5, atunci multimea
a = 0,7; b= 23;
s = ![]()
constituie structura modelului [4]. Scopul va fi acela ca, plecand de la cuplurile (Ci,Vi) asociate diferitelor familii i, sa se determine structura adevarata a modelului. Cu alte cuvinte, plecand de la un spatiu esantion definit de multimea cuplurilor (Ci,Vi) sa se determine structura adevarata a modelului in spatiul cu trei dimensiuni al structurilor
a , b, s . Aici intervine "inductia"statistica.
1.4. Inductia statistica
Obiectul inductiei statistice este de a determina o procedura care, pornind doar de la observatiile statistice de care dispunem, sa permita trecerea de la spatiul esantion la spatiul structurilor. Odata ce modelul a fost ales, se admite ca exista un triplet (a, b, s ) care permite reprezentarea exacta a procesului prin care valorile variabilelor observate au fost determinate. In cursul inductiei statistice modelul nu se mai modifica. Procedura aleasa - asa cum se va vedea in continuare - va consta in obtinerea de estimatori pentru parametrii a si b care sa permita determinarea celor mai bune valori reale ale acestor parametri. Aceste valori se vor aprecia, in general, cu ajutorul unor "intervale de incredere" construite la un prag de semnificatie (a) dat. De exemplu, in modelul [4] se va gasi ca aI[0,64;0,78] si bI[20;27] cu o probabilitate de 95% (s-a considerat a=5%). Se poate estima si abaterea medie patratica (s) a variabilei aleatoare εi. Se va vedea rolul important jucat de aceasta variabila aleatoare in modelul econometric.
1.5. Identificarea modelului
Consideram din nou modelul Ci=aVi+b+εi. Sa presupunem ca procedura utilizata, pornind de la informatia detinuta, adica de la cuplurile (Ci,Vi), i=1,2, nu conduce la o solutie unica, ci la doua structuri distincte: s0= a0,b0,s0 , s1 = a1,b1,s1 . Deorece legea de probabilitate pentru ε precizeaza si legea de probabilitate pentru C, fiecare structura (tinand cont de valorile exogenelor si de legea lui ε) conduce la o lege de probabilitate pentru C. Presupunem ca structurile s0 si s1 conduc la aceeasi lege de probabilitate pentru consumul C. Sunt posibile doua cazuri:
|
s0 si s1 sunt distincte si nu putem alege intre ele. Se spune ca structurile considerate nu sunt "identificabile" si, ca urmare, modelul nu este identificabil. Din aceasta cauza nu vom putea determina valorile parametrilor care figureaza in model;
s0 si s1 nu sunt distincte, intersectia lor nu este vida. Acestea vor permite identificarea unei parti a parametrilor modelului (cei care apartin intersectiei). Se spune ca cele doua structuri sunt echivalente, dar nu permit o identificare completa a modelului.
Problema identificarii este importanta mai ales in cazul modelelor cu ecuatii multiple.
1.6. Previziunea variabilei endogene
Interesul unui model a carui structura a fost determinata consta in a-l utiliza pentru previzionarea variabilelor endogene - intr-o etapa viitoare sau intr-o circumstanta data, daca este vorba despre observatii luate la acelasi moment-, atunci cand cele exogene au fost fixate. De exemplu, daca dorim sa studiem evolutia importurilor (Y) in functie de produsul intern brut (X1) si de nivelul stocurilor (X2), modelul econometric este:
yt=a1x1t+a2x2t+b+εt, t=1,2,,T
unde t este timpul. Datele istorice (pe perioada 1990-2005) despre Y, X1 si X2 (observatiile fiind anuale) permit determinarea parametrilor modelului. Sa presupunem ca am gasit estimatiile punctuale:

Modelul "estimat" este: ![]() . Daca dorim sa facem o previziune a importurilor
pentru anul 2007, trebuie sa stim PIB-ul si nivelul stocurilor in anul 2007.
Presupunind ca aceste variabile exogene sunt x1=1030 si x2=12,7
vom avea ca previziune pentru y:
. Daca dorim sa facem o previziune a importurilor
pentru anul 2007, trebuie sa stim PIB-ul si nivelul stocurilor in anul 2007.
Presupunind ca aceste variabile exogene sunt x1=1030 si x2=12,7
vom avea ca previziune pentru y:
y2007=(0,14).1030+(0,6).(12,7)+6
sau, in general, ![]() , unde θ este perioada de previziune.
, unde θ este perioada de previziune.
Observatie. Asupra valorii previzionate trebuie sa remarcam:
valorile exogenelor x1θ, x2θ au fost alese arbitrar, eventual tinind cont de evolutia lor trecuta;
specificarea modelului nu poate fi perfecta, forma functiei alese pentru a explica evolutia lui y neputind fi suficient de precisa;
este posibil ca variabilele explicative (exogene) ale variabilei endogene (explicate), sa nu mai intervina in acelasi mod ca in perioada 1990-2005, cind s-a studiat legatura dintre ele. Este posibil sa aiba loc un soc, o ruptura care sa perturbe echilibrul dintre variabilele care explica fenomenul, la momentul previziunii.
Este evident ca toate aceste cauze pot constitui surse de eroare a previziunii. Vom vedea care sunt metodele de a minimiza eroarea de previziune.
Rezumatul capitolului I
Pentru constructia si utilizarea unui model econometric, se parcurg urmatoarele etape:
specificarea modelului (gasirea formularii matematice definitive a legaturii dintre variabilele care descriu fenomenul sau procesul economic studiat);
estimarea parametrilor si testarea modelului cu ajutorul statisticilor (seriilor de date observate) deja cunoscute;
previziunea variabilei endogene.
1.7. Vocabular uzual
Daca sunteti familiarizati cu statistica matematica, puteti trece la capitolul II. In caz contrar, va reamintim aici citeva notiuni de baza. Lectura acestui paragraf credem ca va va incita sa revedeti cursul de Statistica matematica.
Nor de puncte - Fiind data o serie de date statistice in care valorile (xi,yj) apar efectiv de nij ori putem reprezenta intr-un plan toate aceste valori prin puncte de coordonate (xi,yj) afectate de coeficientii nij , obtinandu-se astfel un nor de puncte.
Ajustare - Reprezentarea grafica a seriilor de date economice conduce frecvent la figuri putin lizibile si greu de interpretat din cauza variatiilor pe termen scurt, numeroase si sensibile, dar fara o semnificatie importanta. Metodele matematice numite "de ajustare" permit obtinerea unei curbe simple, cat mai apropiata posibil de multimea de puncte furnizate de observatiile empirice disponibile.
Ajustare liniara - Atunci cand reprezentarea grafica a unei serii statistice duble da un nor de puncte de forma alungita, se incearca obtinerea unei aproximari bune a acestei serii cu ajutorul unei drepte, realizandu-se astfel o ajustare liniara. Exista mai multe metode pentru gasirea acestei drepte:
- metoda
grafica (se determina punctul mediu M ale carui coordonate sunt ![]() si se
traseaza dreapta care pare a fi cea mai reprezentativa a seriei,
determinand ecuatia Y=aX+b.
Aceasta metoda este ambigua pentru ca nu tine cont de
ponderea fiecarui punct in norul de puncte);
si se
traseaza dreapta care pare a fi cea mai reprezentativa a seriei,
determinand ecuatia Y=aX+b.
Aceasta metoda este ambigua pentru ca nu tine cont de
ponderea fiecarui punct in norul de puncte);
- metoda lui Mayer (se regrupeaza punctele norului in doua submultimi carora li se determina punctele medii M1 si M2. Dreapta de ajustare este atunci dreapta care trece prin M1 si M2);
- metoda
celor mai mici patrate (consta in a face minima suma
patratelor distantelor de la punctele norului la o dreapta de
ecuatie Y=aX+b numita
dreapta de regresie a lui Y in X. Se arata ca panta
(coeficientul director) acestei drepte este a=cov(X,Y)/Var(X).
Coeficientul b se obtine scriind
ca dreapta de regresie trece prin punctul mediu: ![]() . Procedand la fel se gaseste dreapta de regresie
de ecuatie X=a Y+b , cu a =cov(X,Y)/Var(Y) si
. Procedand la fel se gaseste dreapta de regresie
de ecuatie X=a Y+b , cu a =cov(X,Y)/Var(Y) si ![]() . Cele doua drepte de regresie sunt, in general,
distincte. Compararea lor permite
masurarea nivelului de corelatie al caracteristicilor X si Y. Corelatia se masoara cu coeficientul de
corelatie r=cov(X,Y)/s(X)s(Y). Se
constata ca r2=aa si ca r variaza intre -1 si
1. r2 masoara
unghiul dintre cele doua drepte de regresie, care coincid daca r2=1, adica
. Cele doua drepte de regresie sunt, in general,
distincte. Compararea lor permite
masurarea nivelului de corelatie al caracteristicilor X si Y. Corelatia se masoara cu coeficientul de
corelatie r=cov(X,Y)/s(X)s(Y). Se
constata ca r2=aa si ca r variaza intre -1 si
1. r2 masoara
unghiul dintre cele doua drepte de regresie, care coincid daca r2=1, adica ![]() . Caracteristicile X
si Y sunt corelate maximal cand
. Caracteristicile X
si Y sunt corelate maximal cand ![]() este apropiat de 1).
este apropiat de 1).
In afara faptului de a da o reprezentare mai mult sau mai putin satisfacatoare legaturii dintre X si Y, importanta ajustarii liniare este de a permite previziuni statistice, asociind lui X o valoare probabila a lui Y prin relatia Y=aX+b.
Probabilitate - Fiind data o multime finita W, numim probabilitate pe W orice aplicatie p a lui P(W - multimea partilor lui W - in intervalul [0,1 care verifica trei conditii:
- p(A) 0, pentru AI P W
- p(W)=1
- p(A B)= p(A)+ p(B), daca A,BI P W), A B=F
W se numeste univers (sau univers de
probabilitati). W inzestrat cu probabilitatea p se numeste spatiu probabilizat. Orice parte a lui W este un eveniment. Un singleton (multime ce
contine un singur element) al lui W se
numeste eveniment elementar sau eventualitate. W este evenimentul cert. F este evenimentul imposibil. ![]() este evenimentul
complementar lui A in W (se numeste eveniment contrar lui A). Daca A B=F, evenimentele A si B sunt incompatibile.
este evenimentul
complementar lui A in W (se numeste eveniment contrar lui A). Daca A B=F, evenimentele A si B sunt incompatibile.
Variabila aleatoare - Daca W este un univers finit, numim "variabila aleatoare" orice aplicatie X: W R ( a lui W in multimea numerelor reale). Multimea valorilor lui X, adica X(W se numeste universul imagine. Atentie!- o variabila aleatoare nu este o variabila, ci o aplicatie! Se observa ca nu este necesar sa cunoastem o probabilitate pe W pentru a defini o variabila aleatoare pe W
Legea de probabilitate a unei variabile aleatoare - Daca universul finit W este inzestrat cu o probabilitate p, iar X este o variabila aleatoare definita pe W, numim lege de probabilitate a variabilei aleatoare X, aplicatia px: X(W [0,1 care asociaza oricarui xIX(W probabilitatea evenimentului "multimea antecedentelor lui x prin X". Aceasta multime X-1(x) este notata (X=x). Legea de probabilitate a lui X, notata px este definita prin px: X(W [0,1 , x p(X=x). A studia o variabila aleatoare inseamna a-i descoperi legea sa de probabilitate.
Functie de repartitie - Daca universul finit W este inzestrat cu o probabilitate p, iar X este o variabila aleatoare definita pe W, se asociaza acestei variabile aleatoare
functia F:R [0,1 definita prin F(x)=p(X<x)
numita functie de repartitie a variabilei aleatoare X. Evenimentul (X<x) este imaginea intervalului ![]() prin functia X. Functia de repartitie este
o functie in scara.
prin functia X. Functia de repartitie este
o functie in scara.
Speranta matematica - Daca X este
o variabila aleatoare definita pe universul finit W, inzestrat cu probabilitatea p, universul imagine este o multime finita si ia
valorile xi, i=1,2,,n.
Legea de probabilitate a lui X
asociaza fiecarui xi
probabilitatea pi=p(X=xi).
Se numeste speranta matematica a variabilei aleatoare X,
numarul real  . E(X) este media in probabilitate a
valorilor luate de variabila aleatoare X.
E(.) este un operator liniar.
. E(X) este media in probabilitate a
valorilor luate de variabila aleatoare X.
E(.) este un operator liniar.
Varianta -
Daca X este o variabila
aleatoare definita pe universul finit W, inzestrat cu probabilitatea p, universul imagine este o multime
finita si ia valorile xi,
i=1,2,,n. Legea de probabilitate a lui X asociaza fiecarui xi
probabilitatea pi=p(X=xi).
Se numeste varianta a variabilei aleatoare X, numarul real pozitiv ![]() . Varianta este media in probabilitate a patratului
distantelor de la xi
la media lor. Radacina patrata (radicalul) lui Var(X) este ecartul-tip al variabilei
aleatoare X, notat sx
. Varianta este media in probabilitate a patratului
distantelor de la xi
la media lor. Radacina patrata (radicalul) lui Var(X) este ecartul-tip al variabilei
aleatoare X, notat sx
Momente conditionate - Se considera vectorul aleator ![]() , cu repartitia
, cu repartitia ![]() ,
, ![]()
![]()
![]() si variabila
aleatoare conditionata (X/Y=yj)
cu repartitía
si variabila
aleatoare conditionata (X/Y=yj)
cu repartitía 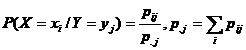 . Momentul de ordinul k
al variabilei aleatoare X
conditionat de Y=yj
este momentul initial de ordinul k
al variabilei aleatoare conditionate (X/Y=yj):
. Momentul de ordinul k
al variabilei aleatoare X
conditionat de Y=yj
este momentul initial de ordinul k
al variabilei aleatoare conditionate (X/Y=yj):
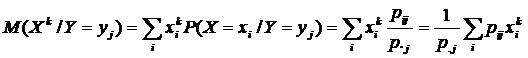
Similar se defineste momentul de ordinul k al variabilei aleatoare Y conditionat de X=xi.
Pentru k=1 se obtin mediile conditionate:
![]()
Se pot defini variabilele aleatoare "medii conditionate" astfel:
- variabila aleatoare "media lui X conditionata de Y", cu repartitia:
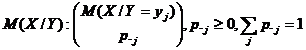
-variabila aleatoare "media lui Y conditionata de X" , cu repartitia:

Regresie - Se numeste regresia variabilei aleatoare X in raport cu Y, variabila aleatoare M(X/Y) cu multimea
valorilor posibile: M(X/Y=y), ![]()
Similar,
regresia variabilei aleatoare Y in
raport cu X este: M(Y/X=x), ![]()
Daca M(X/Y)=aX+b sau M(Y/X)=cY+d se spune ca regresia este liniara
Repartitía normala - Variabila aleatoare X urmeaza o repartitie
normala de parametri m si σ (se mai scrie si ![]() ) daca densitatea ei de probabilitate (derivata
functiei de repartitie) este:
) daca densitatea ei de probabilitate (derivata
functiei de repartitie) este:
![]()
![]()
![]()
![]() σ>0
σ>0
Pentru m=0 si σ =1 se obtine repartitia normala "normata" N(0,1), cu densitatea de probabilitate:
![]()
![]()
Se arata ca
parametri m si σ2 sunt media
(speranta matematica), respectiv dispersia (varianta) variabilei
aleatoare ![]() .
.
Repartitia
χ2 (hi-patrat) cu n
grade de libertate - Variabila aleatoare X urmeaza legea de
repartitie hi-patrat cu n
grade de libertate (se mai scrie si ![]() ) daca densitatea ei de repartitie este:
) daca densitatea ei de repartitie este:
 x>0,
x>0, ![]()
Daca variabilele aleatoare
![]() i=1,2,,n sunt independente, atunci variabila aleatoare
i=1,2,,n sunt independente, atunci variabila aleatoare 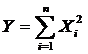 urmeaza legea de repartitie H(n).
urmeaza legea de repartitie H(n).
Repartitia Student cu n grade de libertate S(n) - Variabila aleatoare X urmeaza legea de repartitie Student cu n grade de libertate daca densitatea ei de repartitie este:

![]()
![]()
Daca
variabilele aleatoare ![]()
![]() sunt independente, atunci variabila aleatoare
sunt independente, atunci variabila aleatoare  .
.
Repartitia Fisher-Snedecor F(n1,n2) - Variabila aleatoare X urmeaza legea de repartitie Fisher-Snedecor cu n1 si n2 grade de libertate daca densitatea ei de repartitie este:
![]()
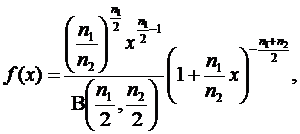 x>0,
x>0, ![]()
Daca
variabilele aleatoare ![]() si
si 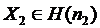 sunt independente,
atunci variabila aleatoare
sunt independente,
atunci variabila aleatoare  .
.
| Contact |- ia legatura cu noi -| | |
| Adauga document |- pune-ti documente online -| | |
| Termeni & conditii de utilizare |- politica de cookies si de confidentialitate -| | |
| Copyright © |- 2025 - Toate drepturile rezervate -| |
|
|
|||
|
|||
Referate pe aceeasi tema | |||
|
| |||
|
|||
|
|
|||